



Better Data Management in Health Tech

While working with a top strategy firm and a major German Healthcare company building the healthcare product Fern Health, we engineered a solution that solved several challenges often encountered in health tech. This product is used by multiple users with different needs and requires data from several different healthcare-compliant data sources.
Early on in our Experiment-Driven Design process, it became apparent that we were solving problems for more than just a single user. The system was predicated on a system of complex interactions between health care providers, the patient, their caregivers, healthcare advisors, etc. This is a common trend that we have seen across many Philosophie projects in digital healthcare.
From an engineering perspective, we encountered a common problem that is often overlooked: these multi-user interactions also need to be compliant with many different legal regulations (e.g. HIPAA). Often, this compliance is delegated to integration partners that specialize in compliant data storage for these different journeys, use cases, etc.
For every request the client application made to our server, we had to pull in and combine data from both our own proprietary database as well as from a series of compliant storage providers. We realized quickly that we needed a cohesive approach to interact with this data programmatically because without a thoughtful architecture we would end up with a spider web of overlapping and hard to follow network requests:
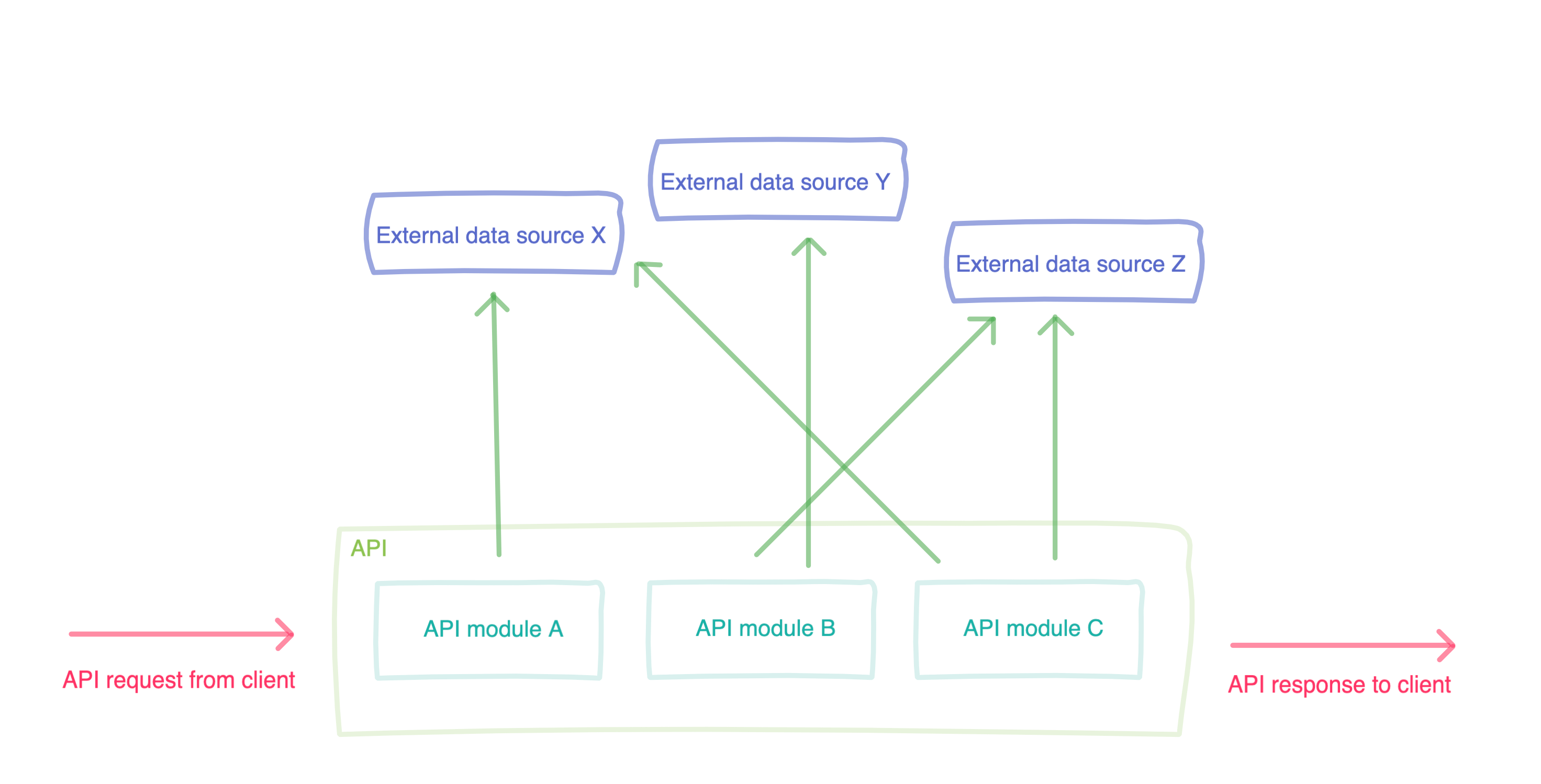
Bad 🙁
In order to make this system scalable, we ended up leveraging the Decorator and Proxy design patterns to combine data from a series of external sources behind a standardized internal interface, allowing our application to interact with all these different data sources and data points in a simple and predictable way. This empowered us to iterate much more quickly without worrying about creating brittle, bug-prone code.
That is, whenever our client app made a request to our API, the `User` object passed through that request would be wrapped with a decorator. That decorator, in turn, added additional attributes to that `User` instance that mapped to data from our external compliant data sources, providing a single API interface for the rest of our application to use.
For example, even though a data point such as `medical_history` was data sitting on another server somewhere (because we legally couldn’t store that in our own database), if a module inside our application required that information, it could simply call `user.medical_history` rather than having to make a raw API request to that external system. This enabled us to build at scale while keeping data between different systems highly decoupled, resulting in a system that looked like this:
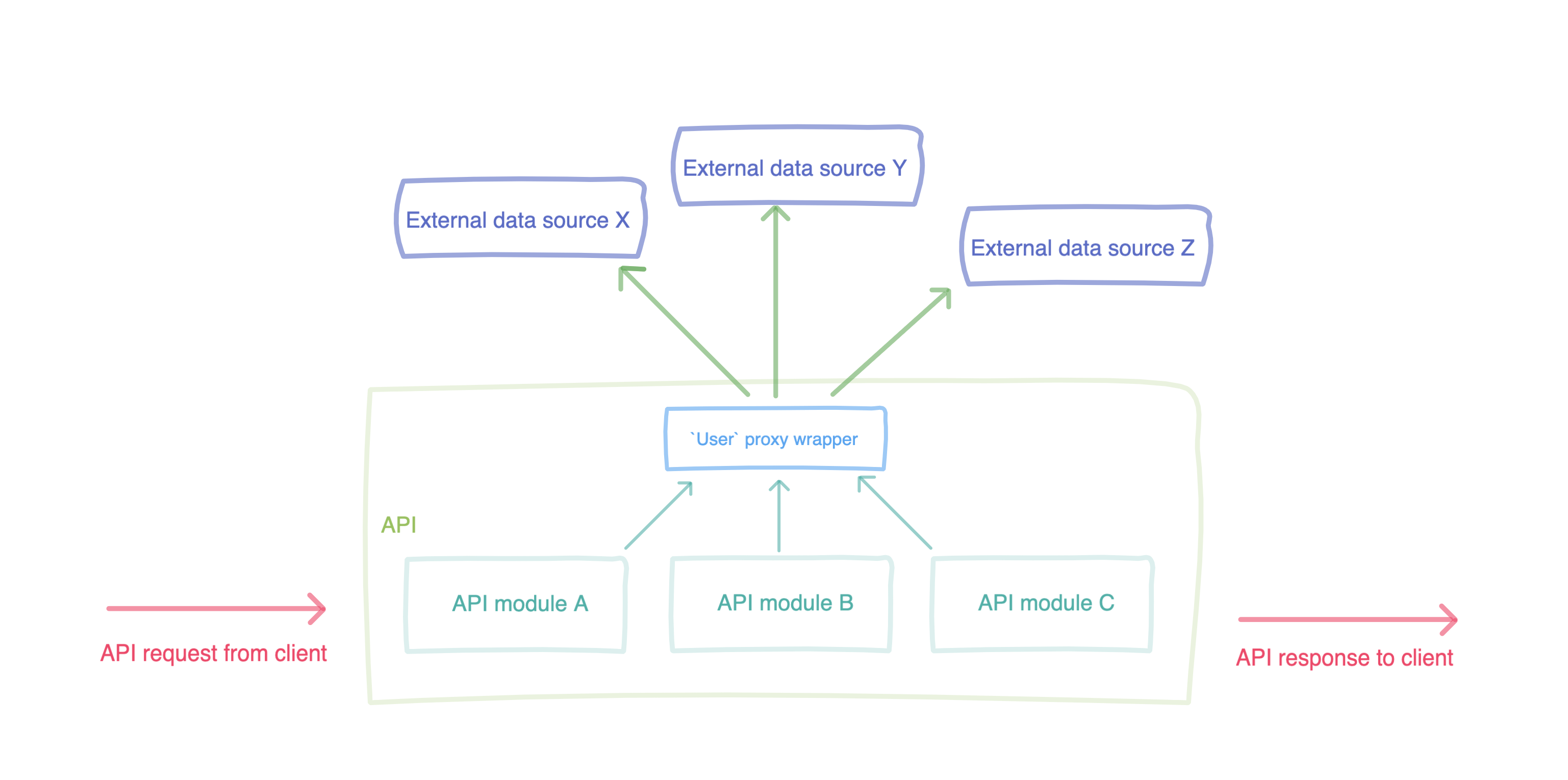
Better 🙂
Through this approach, we could add and/or modify as many external data sources as needed and abstract that away from the rest of our internal code, empowering us to focus entirely on our own product’s value-add. For example, twice more in the project we had to add external compliant data sources and rather than retrofitting disparate API calls throughout the codebase, we were able to simply modify an internal method inside of this User proxy wrapper.
This is a good example of how a little upfront thought and proper software architecture can save a lot of time and pain down the road. Building impactful products in health tech is a great opportunity to incorporate thoughtful software design to support iterating on end-users’ experiences.

Related content
Data Engineering
Empower your business with data-driven decision-making through our insightful data engineering solutions.
Mendix
We leverage Mendix's low-code platform to deliver customizable agile solutions that perfectly match your needs.
SLA-based Managed Services
We proactively monitor endpoints and keep systems up-to-date, preventing issues and ensuring optimal performance.



Stay up to date with InfoBeans
Insights from our team of experts who deliver digital software day in and day out.
![]() Thank you for signing up!
Thank you for signing up!
![]() Thanks a lot for your interest. You are already a subscriber. You will receive your first newsletter soon.
Thanks a lot for your interest. You are already a subscriber. You will receive your first newsletter soon.
