



How to test AI concepts with user research

The full version of this blog post originally appeared on UX Collective’s Medium on March 2, 2017. It has been edited slightly.
It is clear that intelligent algorithms such as deep learning, machine learning, artificial intelligence, etc. will have a major impact on the world. However, what isn’t clear is how these technologies can be used to solve real problems for people.
Patrick, your friendly robot helper, as designed by my amazing teammates at Philosophie (now InfoBeans), Jamie, and Leah.
At InfoBeans we work on experiences that help humans in their day-to-day tasks. We hope to join the benefits of intelligent algorithms with the things that humans do best: deal with complex and creative endeavors that solve their problems towards some purpose.
In this post we will take you through the methods we have used at InfoBeans to validate how intelligent algorithms could be used to solve real-world problems.
Centaurs or cyborgs?
Our inspiration comes from intelligent algorithms being used in the domain of chess, one of the first ‘hard’ games to be conquered by deep learning. After Garry Kasparov was beaten by Deep Blue he was inspired to start a new form of chess that combines humans and computers together called Advanced Chess. It is also referred to as centaur, advanced, and cyborg chess.
As in the centaur model, we look to the intelligent algorithms as assistants, helpers, and to help the humans they work with achieve the human’s purposes. Not the other way around. It is much like a partnership since the algorithms need to learn from the human counterpart as well.
In this article, I try to avoid talking about particular technologies or techniques because people don’t care what you use as long as it helps solve a problem. Generally, the systems we are considering use supervised or semi-supervised learning techniques, but it could really be anything.
Always get started with a problem
First, as with any endeavor, you need to have a real problem that you are trying to solve.
At this stage of intelligent algorithms, you should be targeting the parts of a problem that are busywork. By busywork, I mean those aspects that feel like a routine, are easily documented (say in a manual) or are a heuristic commonly used.
Ideation without an AI PhD
Once you have identified an important problem to solve, you need to ideate solutions with intelligent algorithms in mind. We love the ideating exercise, Crazy Eights and this is a perfect time to do so.
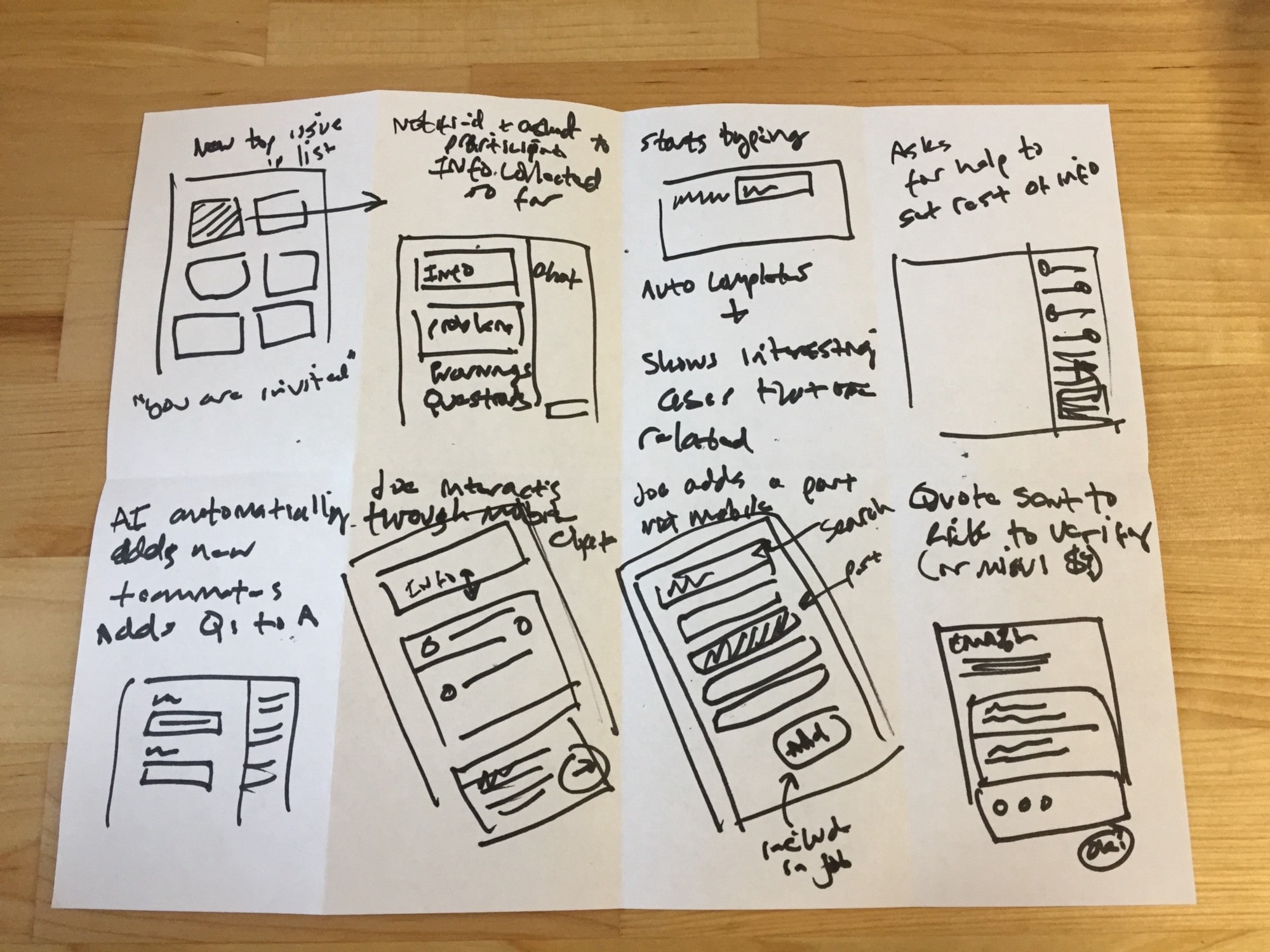
To be clear, we don’t assume that in this process you are building anything yet. We are just looking for ideas that an intelligent algorithm acting like another human helping the person. When sketching (and later prototyping) we will just assume some intelligent algorithm ‘magic’ happens behind the scenes.
There are a few questions you should ask yourself when ideating for intelligent algorithms:
- How would someone else help a person solve this problem?
- What information would they need to solve the problem themselves?
- How will the system describe what it is doing?
- How will the system build trust with the human operator over time?
- How will the human be able to approve or intervene?
- How will feedback be given to the system?
Prototyping the algorithms
Building prototypes (coded or otherwise) with intelligent algorithm support is no different than hiding business or application logic behind an experience.
While designing the prototype you should be asking the same questions as during ideation: how will the system describe what it is doing, how will the human be able to approve or intervene, and how will feedback be given to the system?
A pattern we have used and seen is fake loading and ‘calculating’ experiences. They can help convey the work going into the suggestion, recommendation or decision to start creating trust with the person using it. This is similar to OpenTable’s old ‘looking for a table’ or TurboTax ‘checking for all possible tax breaks’.
We used this concept recently on a project with a Big 4 Consulting company in Field Service Operations. In our research, we were working with a century-old, family-run company that had dispatchers manually setting schedules. We wanted to see if we could use an intelligent algorithm to more efficiently staff field technicians. We needed to make sure that our existing dispatchers were comfortable with technology assisting them and confident in its decisions.
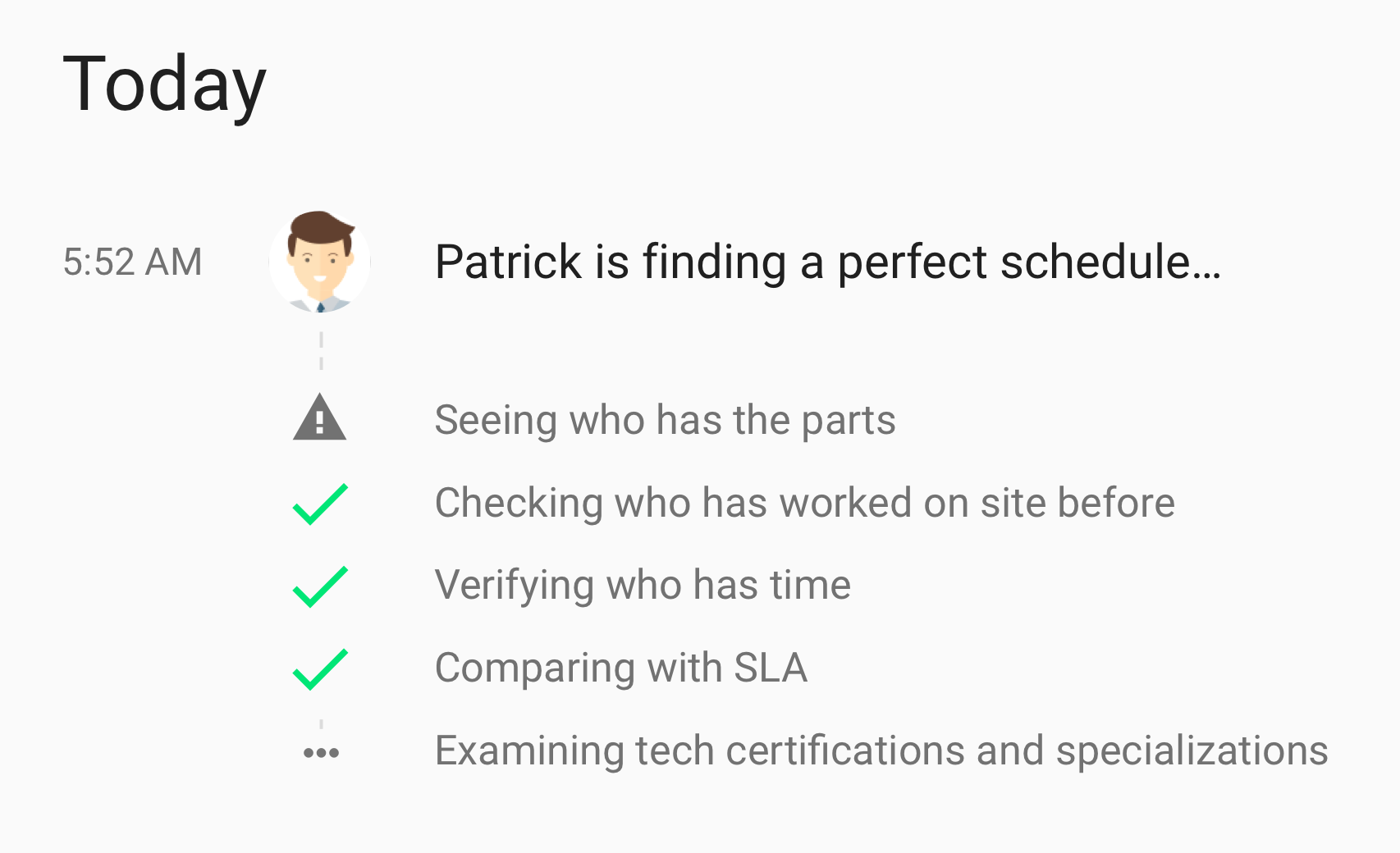
Patrick helping the scheduler find the perfect person to work on the job as part of a timeline.
In this scenario, we slowed down the display to show the dispatcher the steps our robotic dispatcher, ‘Patrick’, would take. Even though ‘Patrick’ would have calculated the options instantaneously, we walk the person through the criteria he is using so they understand.
You also can’t ignore the way that a human will give feedback to the intelligent algorithms (aka supervised learning). If the human has to step in then we need to get the feedback to make the algorithm better. This is generally a ‘why did you make that choice’ type of question to the person using it.
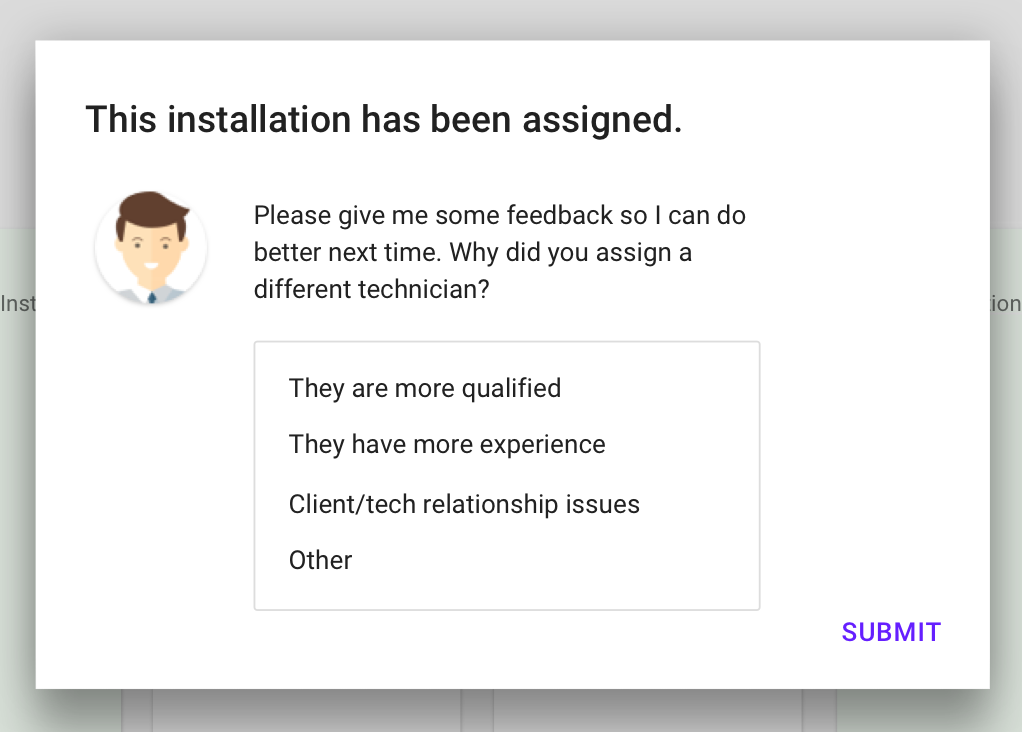
Robots love getting feedback!
In this scenario, if the human dispatcher overwrote ‘Patrick’ we wanted to know why the recommendation was not used. This would then be filtered back into the training data.
Research with humans
Once the prototype is ready, it is time to put it front of real people to see how they perceive the intelligent system working.
When using intelligent algorithms you want to know: 1) if the help they are giving is useful to the problem the person is trying to solve, 2) do they trust the information, and 3) do they feel comfortable giving feedback to the system.
Like any other test plan, you will be focusing on the prototype, but it is important to check in on a few key questions as they go through the experience:
- Think back to the last time you did this, how did you come to that decision?
- Do you trust these suggestions for what to do next?
- How do you think the system decided [action]?
- Was there enough information for you to [take action]?
- How much do you trust the system to make the right decision in the future? It is more or less than before?
Synthesis
Originally, when we were running these tests we tried affinitizing them in different ways. For example by category, but unfortunately, this didn’t lend itself to showing how people felt about using the intelligent algorithm in their work. We wanted to see if they were comfortable with it.

Affinitized, but helpful?
Luckily, Leah, my awesome designer teammate at Philosophie, came up with a great way to understand the intelligent-algorithm-specific observations: put them on a 2×2 for understanding vs. confusion and positive vs. negative sentiment.
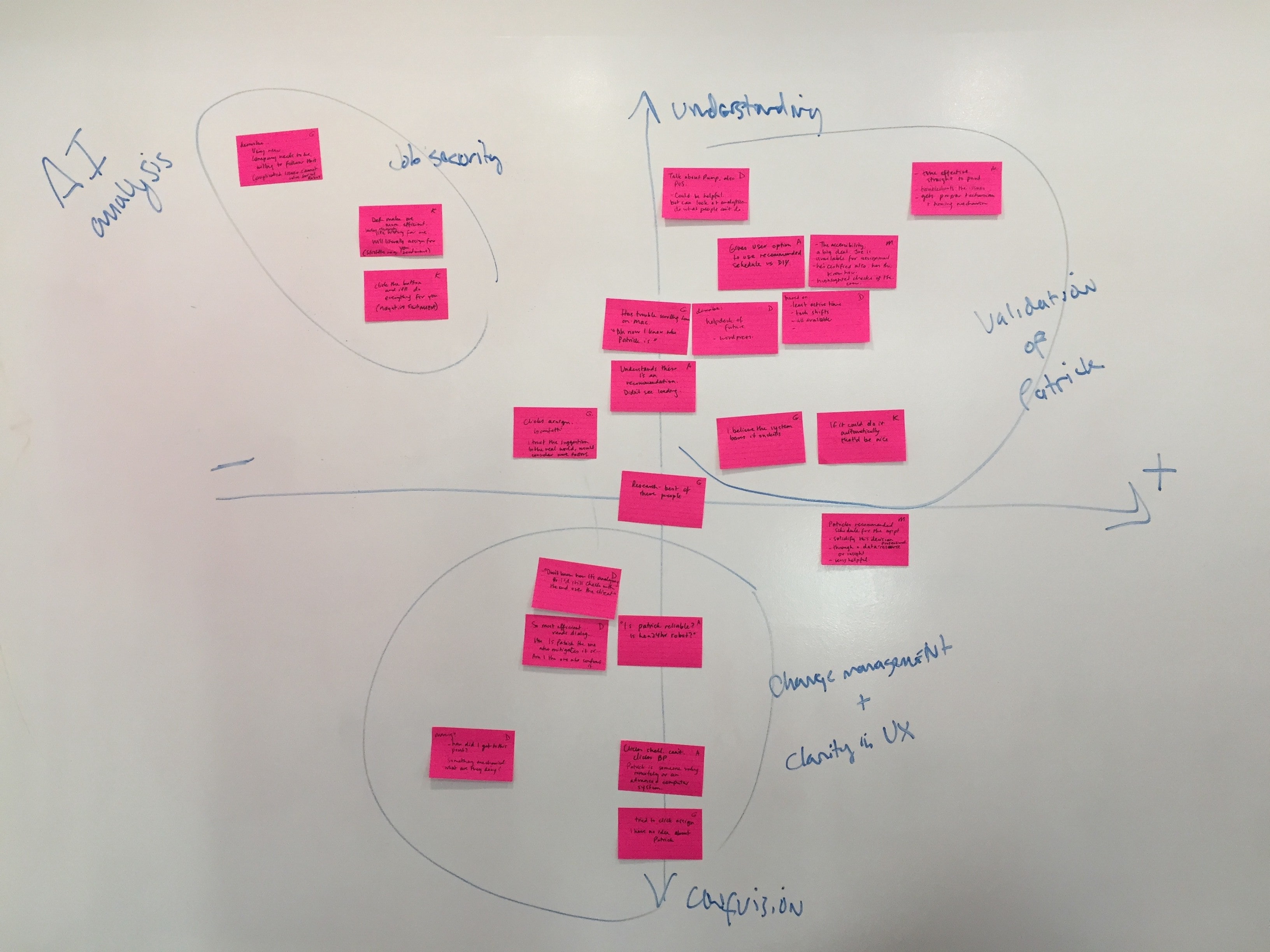
Our new 2×2
When looking at the observations this way we found a few different groupings:
- Positive and understood — validation that the system’s autonomy is helpful
- Negative and understood — concerns about the system taking over their jobs or some distrust of execution
- Negative/positive confusion — issues to address in the UX or via change management of the organization
If you look at the discussions happening about intelligent algorithms, such as self-driving cars, it mimics the set of general topics.
Dystopian possibilities
As we saw in the negative/understood quadrant of the synthesis, people are worried about how intelligent algorithms impact their lives. This isn’t just that they may lose their jobs, but that when a decision is made by an algorithm there may be no chance to understand why.
The ethics of why we are creating systems still matters. People’s purposes are what drive the meaning of technology. Creating a person-less bureaucracy isn’t better than what we have now no matter the amount of additional efficiency we get.
This article on Real Life was a great piece on how intelligent algorithms when used incorrectly can just create a bureaucracy with no people.
I don’t have the answers on what this means, but as creators of these new experiences, it is our duty to try to understand the impact of our work and do what is best for society, not just corporate bottom lines.
What’s next?
There is a lot of focus on technical techniques to create intelligent algorithms, but we need people thinking about how they help people. We have outlined some key questions when doing this research before you build. We hope that you will find it helpful.

Related content
UX/UI Design
Backed by user research and analytics, our approach ensures your design choices are based on real user behavior.
Web3 and Blockchain
Tailored Web3 and blockchain solutions to help companies meet business objectives with scalability and insights.
Mobile Development
We design and build custom enterprise mobile applications from the ground up.



Stay up to date with InfoBeans
Insights from our team of experts who deliver digital software day in and day out.
![]() Thank you for signing up!
Thank you for signing up!
![]() Thanks a lot for your interest. You are already a subscriber. You will receive your first newsletter soon.
Thanks a lot for your interest. You are already a subscriber. You will receive your first newsletter soon.
